So since Microsoft has officially ended extended support for Windows Server on July 15, 2015, that means that you may not be able to get support or any software updates. While many enterprises are working towards being able to migrate applications to more current versions of Windows, alongside initiatives to adopt more cloud services; being able to migrate the deprecated OS to Azure is an option to enable that strategy and provide a place for those applications to run in the meantime.
Be aware though that although Microsoft support (read this) may be able to help you troubleshoot running Windows Server 2003 in Azure, that doesn’t necessarily mean they will support the OS. That said, if you are running vSphere on-premises and still wish to get these legacy systems out of your data center and into Azure, keep reading and I’ll show you how to do it with Zerto.
Please note that I’ve only tested this with the 64-bit version of the OS (Windows Server 2003 R2). EDIT: this has also been verified to work on the 32-bit version of the OS – Thanks Frank!)
The Other Options…
While the next options are totally doable, think about the amount of time involved, especially if you have to migrate VMs at scale. Once you’re done taking a look at these procedures, head to the next section. Trust me, it can be done more easily and efficiently.
- Migrate your VMs from VMware to Hyper-V
- … Then migrate them to Azure. Yes, it’s an option, but from what I’ve read, it’s really just so you can get the Hyper-V Integration Services onto the VM before you move it to Azure. From there, you’ll need to manually upload the VHDs to Azure using the command line, followed by creating instances and mounting them to the disks. Wait – there’s got to be a better way, right?
- Why migrate when you can just do all the work from vSphere, run a bunch of powershell code, hack the registry, convert the disk to VHD, upload, etc… and then rinse and repeat for 10’s or 100’s of servers?
- While this is another way to do it, take a look at the procedure and let me know if you would want to go through all that for even JUST ONE VM?!
- Nested Virtualization in Azure
- Here’s another way to do it, which I can see working, however, you’re talking about nesting a virtual environment in the cloud and perhaps run production that way? While even if you have Zerto you can technically do this, there would have to be a lot of consideration that goes in to this… and likely headache.
Before You Start
Before you start walking through the steps below, this how-to assumes:
- You are running the latest version of Zerto at each site.
- You have already paired your Azure ZCA (Zerto Cloud Appliance) to your on-premises ZVM (Zerto Virtual Manager)
- You already know how to create a VPG in Zerto to replicate the workload(s) to your Azure subscription.
Understand that while this may work, this solution will not be supported by Zerto, this how-to is solely written by me, and I have tested and found this to work. It’s up to you to test it.
Additionally, this is likely not going to get any support from Microsoft, so you should test this procedure on your own and get familiar with it.
This does require you to download files to install (if you don’t have a Hyper-V environment), so although I have provided a download link below, you are responsible for ensuring that you are following security policies, best practices, and requirements whenever downloading files from the internet. Please do the right thing and be sure to scan any files you download that don’t come directly from the manufacturer.
Finally – yeah, you should really test it to make sure it works for you.
Migrating Legacy OS Using Zerto
Alright, you’ve made it this far, and now you want to know how I ended up getting a Windows Server 2003 R2 VM from vSphere to Azure with a few simple steps.
Step 1: Prepare the VM(s)
First of all, you will need to download the Hyper-V Integration Services (think of them as VMware Tools, but for Hyper-V, which will contain the proper drivers for the VM to function in Azure).
I highly suggest you obtain the file directly from Microsoft if at all possible, or from a trustworthy source. At the least, deploy a Hyper-V server and extract the installer from it yourself.
If you have no way to get the installer files for the Hyper-V Integration Services, you can download at your own risk from here. It is the exact same copy I used in my testing, and will work with Windows Server 2003 R2.
- Obtain the Hyper-V Integration Services ISO file. (hint: look above)
- Once downloaded, you can mount the ISO to the target VM and explore the contents. (don’t run it, because it will not allow you to run the tools installation on a VMware-hosted workload).
- Extract the Support folder and all of it’s contents to the root of C: or somewhere easily accessible.
- Create a windows batch file (.bat) in the support folder that you have just extracted to your VM. I put the folder in the root of C:, so just be aware that I am working with the C:\Support folder on my system.
- For the contents of the batch file, change directory to the C:\Support\amd64 folder (use the x86 folder if on 32-bit), then on the next line type: setup.exe /quiet (see example below). The /quiet switch is very important, because you will need this to run without any intervention.
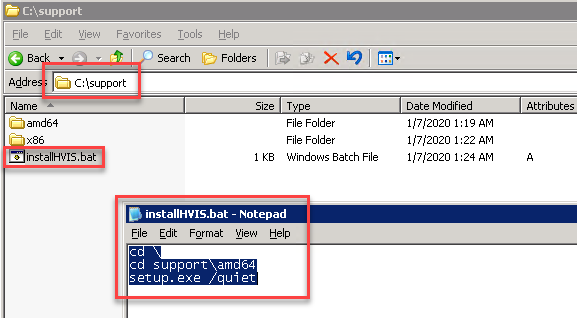
- Save the batch file.
- On the same VM, go to Control Panel > Scheduled Tasks > Add Scheduled Task. Doing so will open the Scheduled Task Wizard.
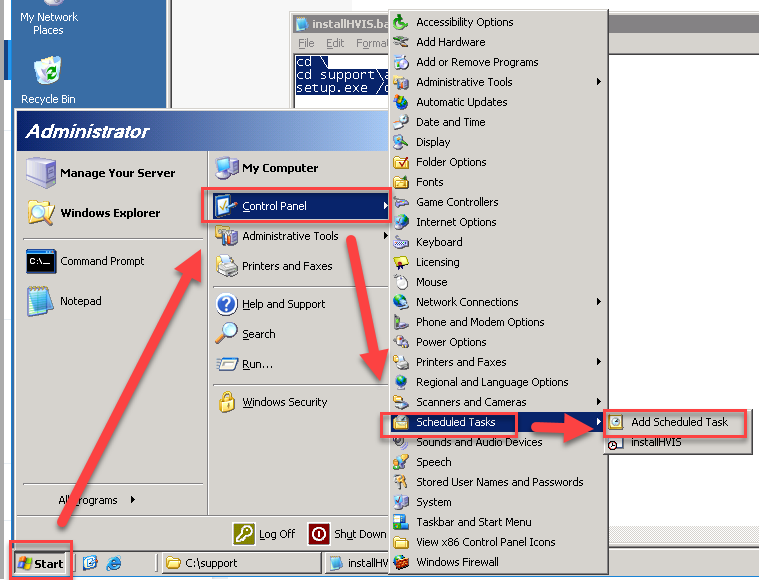
- Click Next
- Click browse and locate the batch file you created in step 5-6, and click open
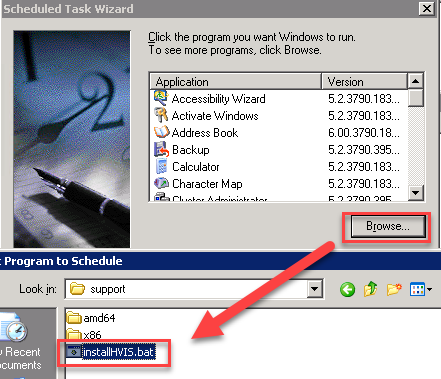
- Select when my computer starts, and click next
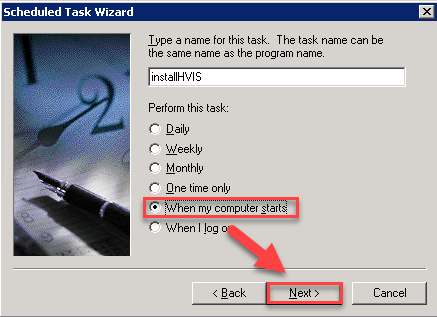
- Enter local administrator credentials (will be required because you will not initially have network connectivity), and click next
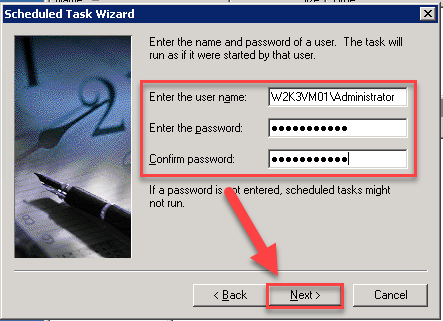
- Click Finish
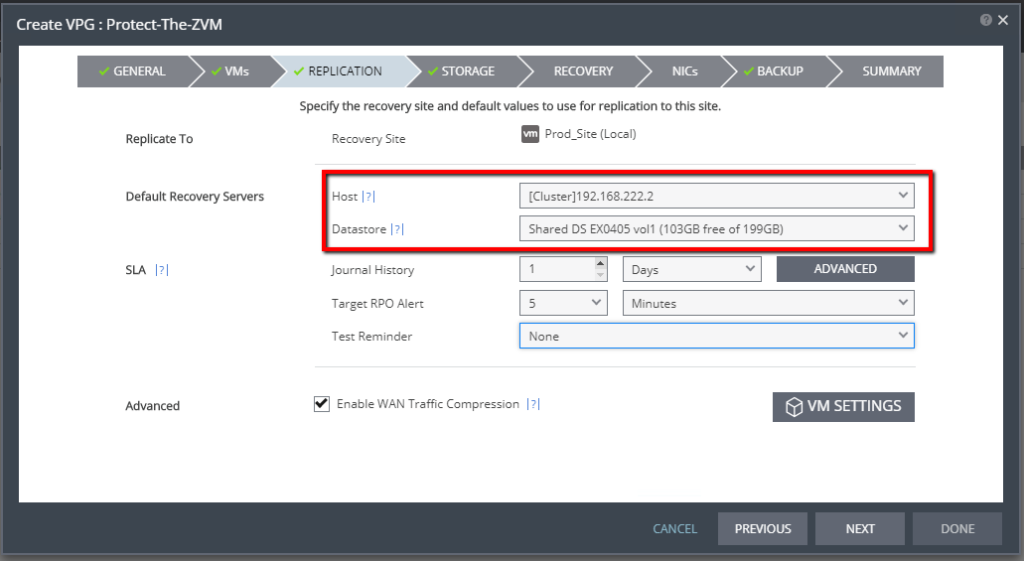
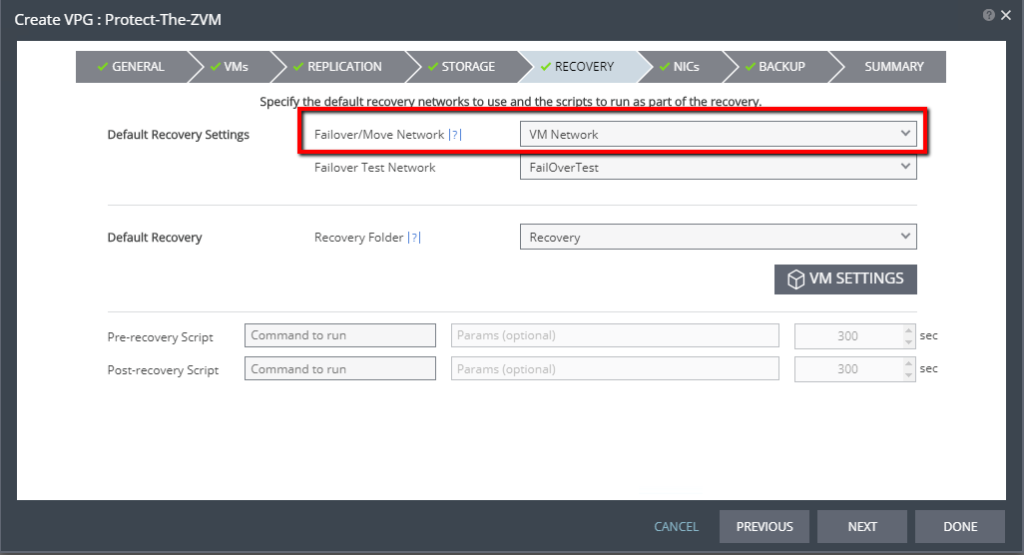
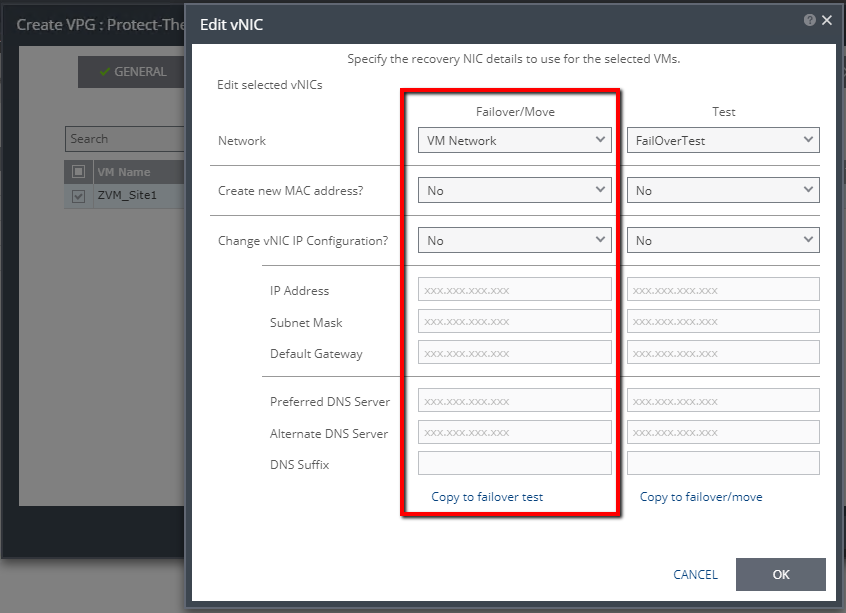
Step 2: Create a VPG in Zerto
The previous steps will now have your system prepared to start replicating to Azure. Furthermore, what we just did, basically will allow the Hyper-V Integration Services to install on the Azure instance upon boot, therefore enabling network access to manage it. It’s that simple.
Create the VPG (Virtual Protection Group) in Zerto that contains the Windows Server 2003 R2 VM(s) that you’ve prepped, and for your replication target, select your Microsoft Azure site.
If you need to learn how to create a VPG in Zerto, please refer to the vSphere Administration Guide – Zerto Virtual Manager documentation.
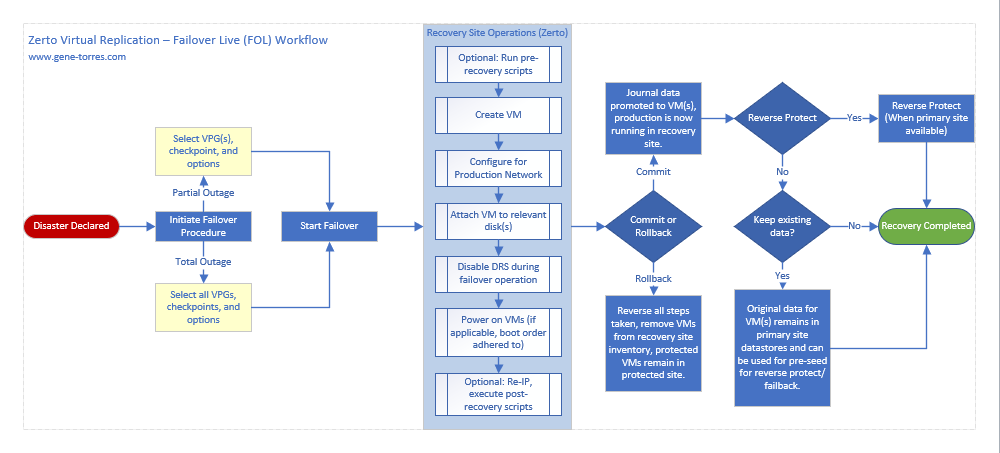
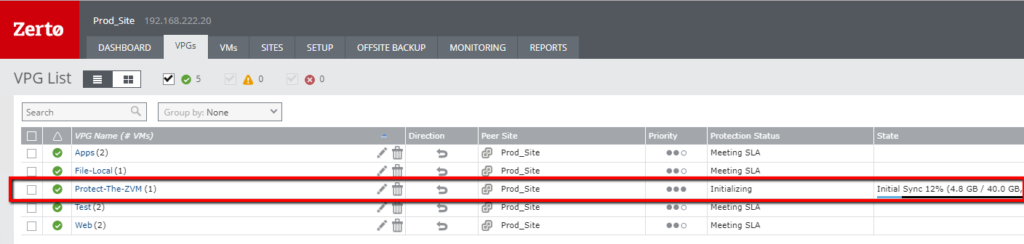
Step 3: Run a Failover Test for the VPG
Once your VPG is in a “Meeting SLA” state, you’re ready to start testing in Azure before you actually execute the migration, to ensure that the VM(s) will boot and be available.
Using the Zerto Failover Test operation will allow you to keep the systems running back on-premises, meanwhile booting them up in Azure for testing to get your results before you actually perform the Move operation to migrate them to their new home.
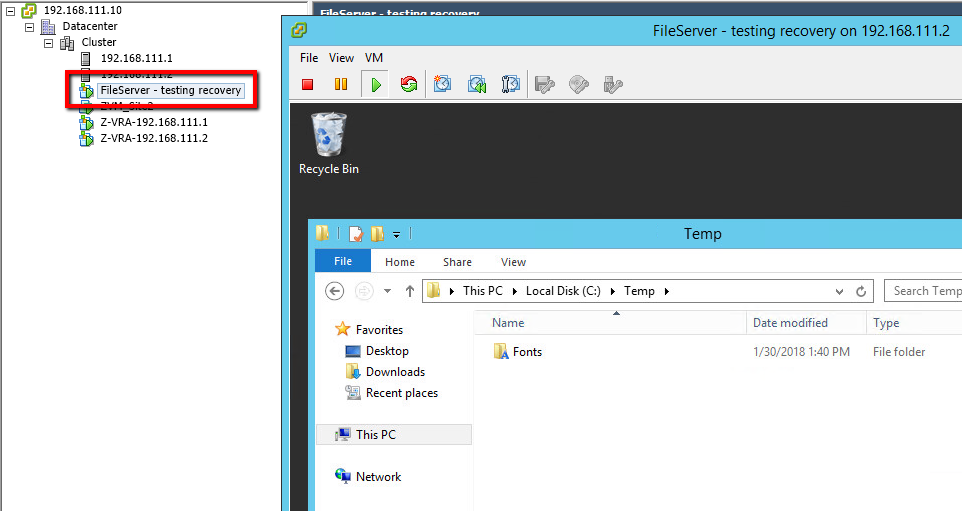
- In Zerto, select the VPG that contains the VM(s) you want to test in Azure (use the checkbox) and click the Test button.
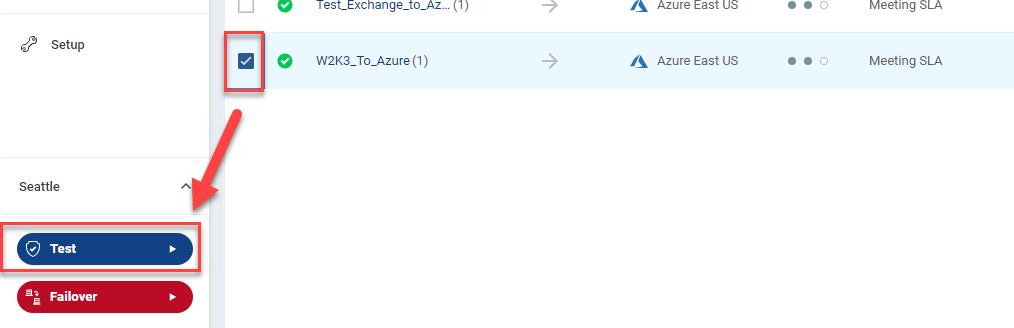
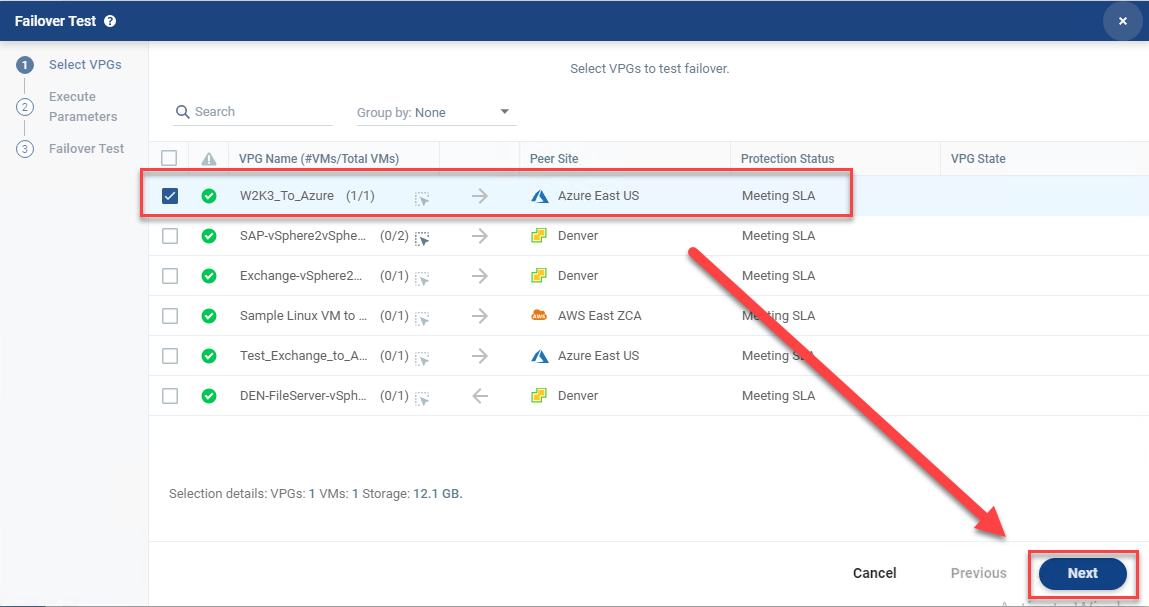
- Validate the VPG is still selected, and click Next.
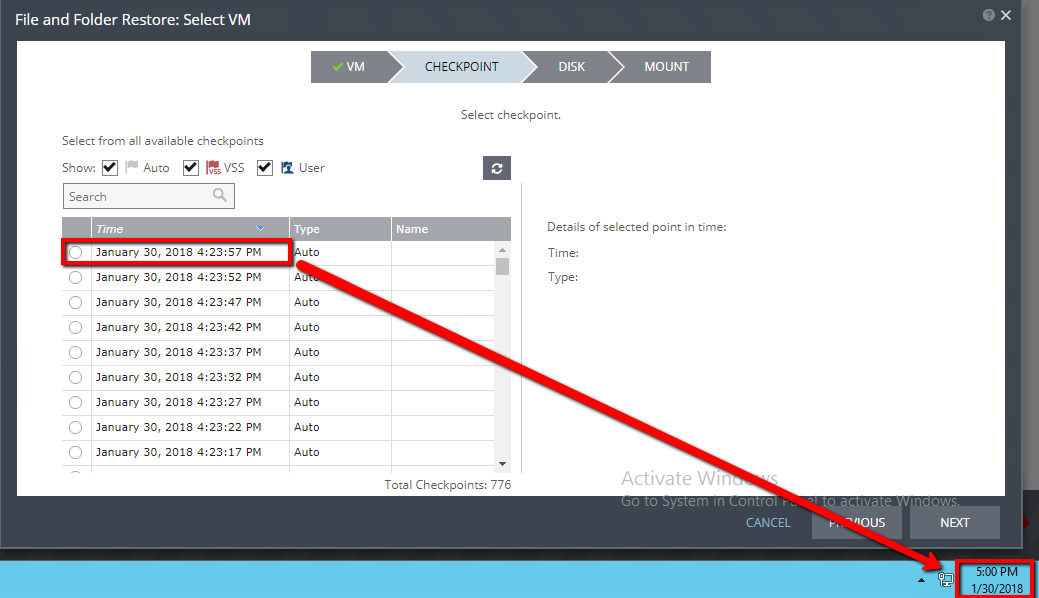
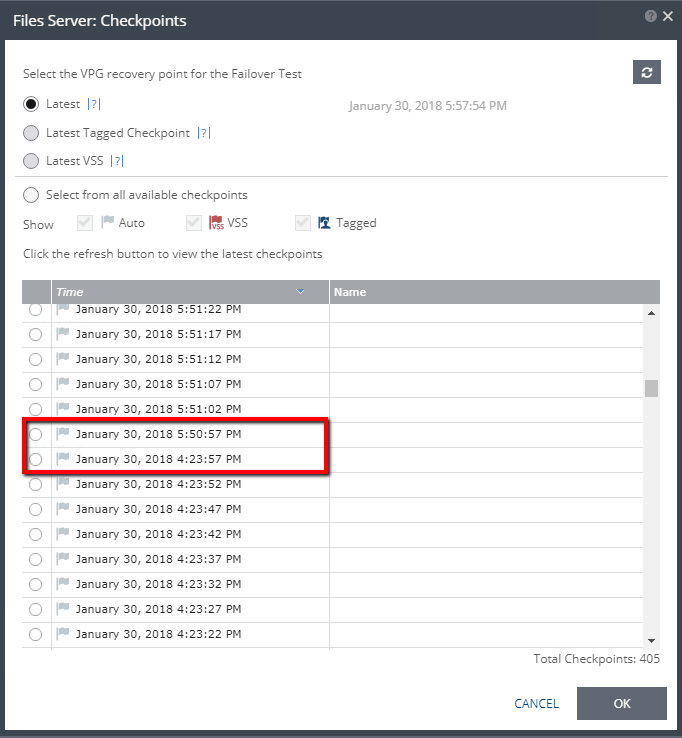
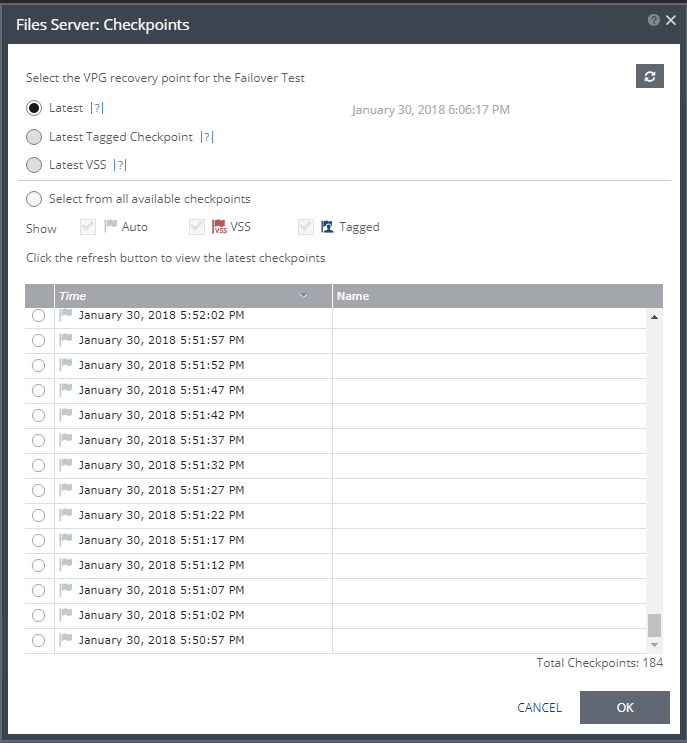
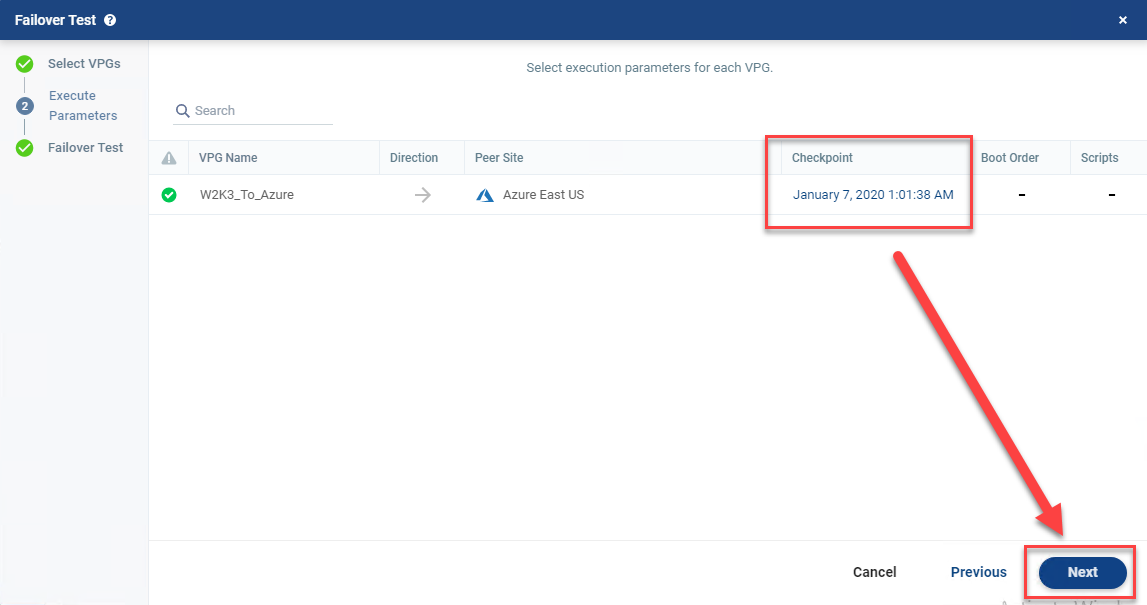
- The latest checkpoint should already be selected for you. Click Next
- Click Start Failover Test.
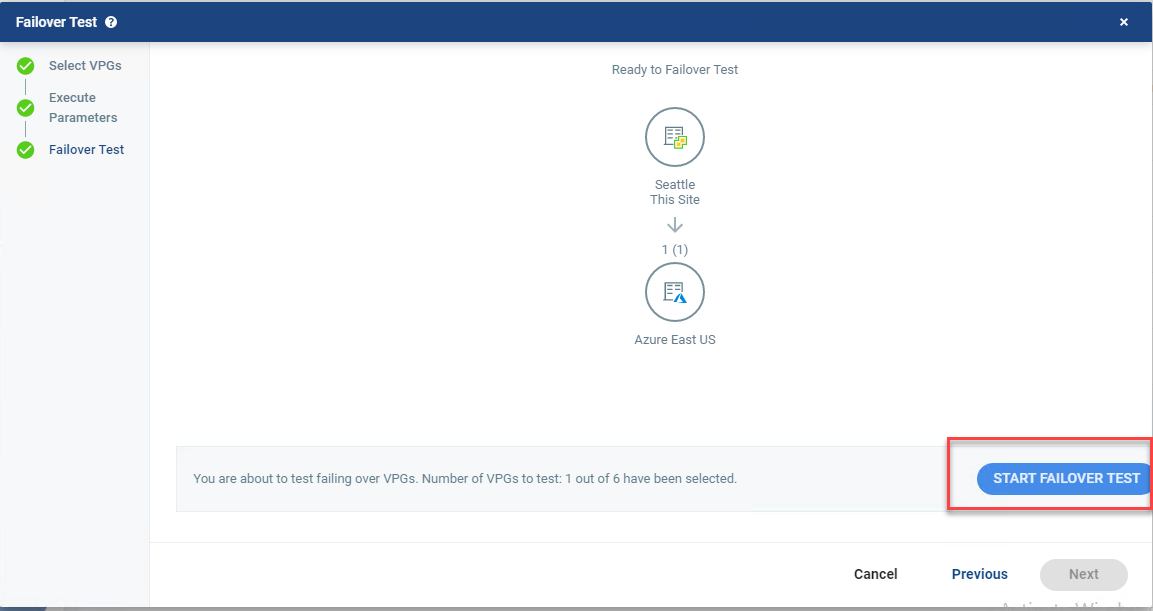
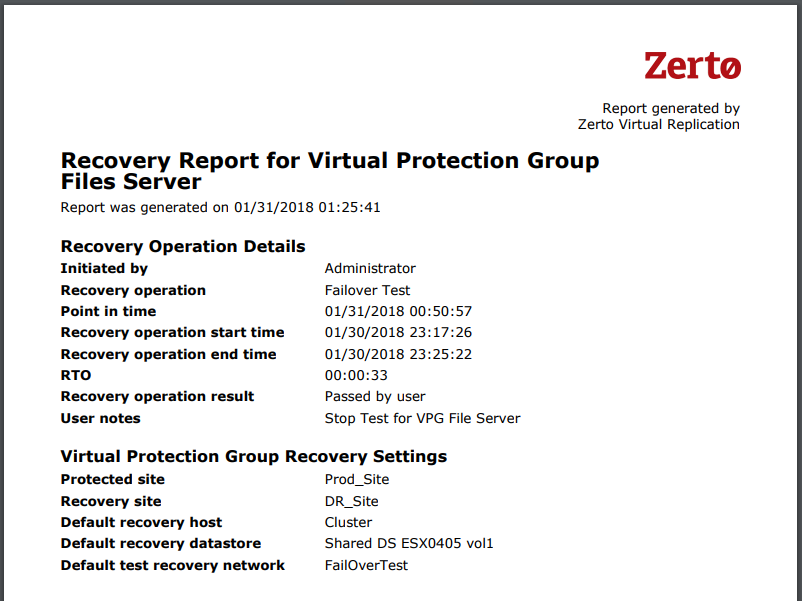
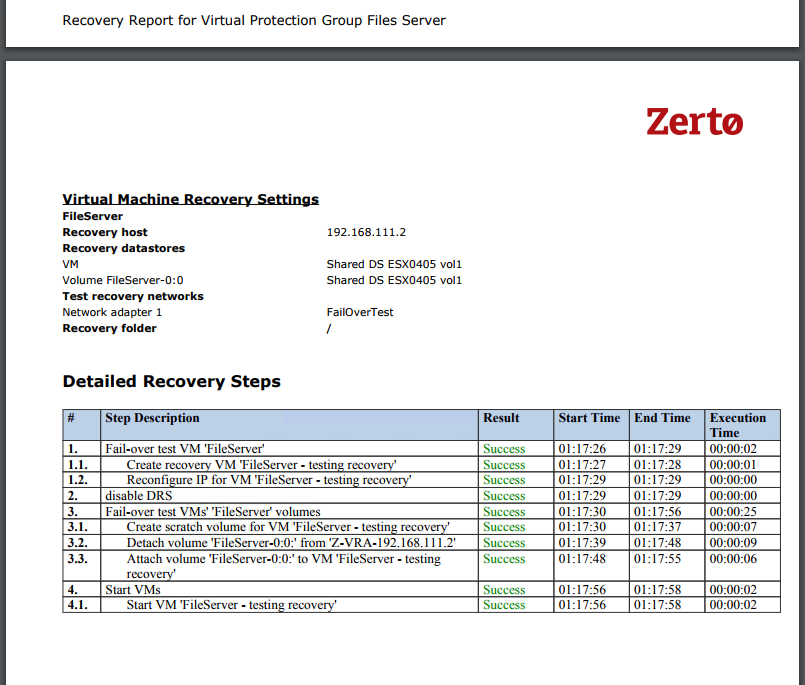
After you click Start Failover Test, the testing operation will start. Once the VM is up in Azure, you can try pinging it. If it doesn’t ping the first time, reboot it, as the Integration Services may require a reboot before you can RDP to it (I had to reboot my test machine).
When you’re done testing, click the stop button in Zerto to stop the Failover Test, and wait for it to complete. At this point, if everything looks good, you’re ready to plan your migration.
If you did anything different than what I had done, remember to document it and make it repeatable :).
Next Steps
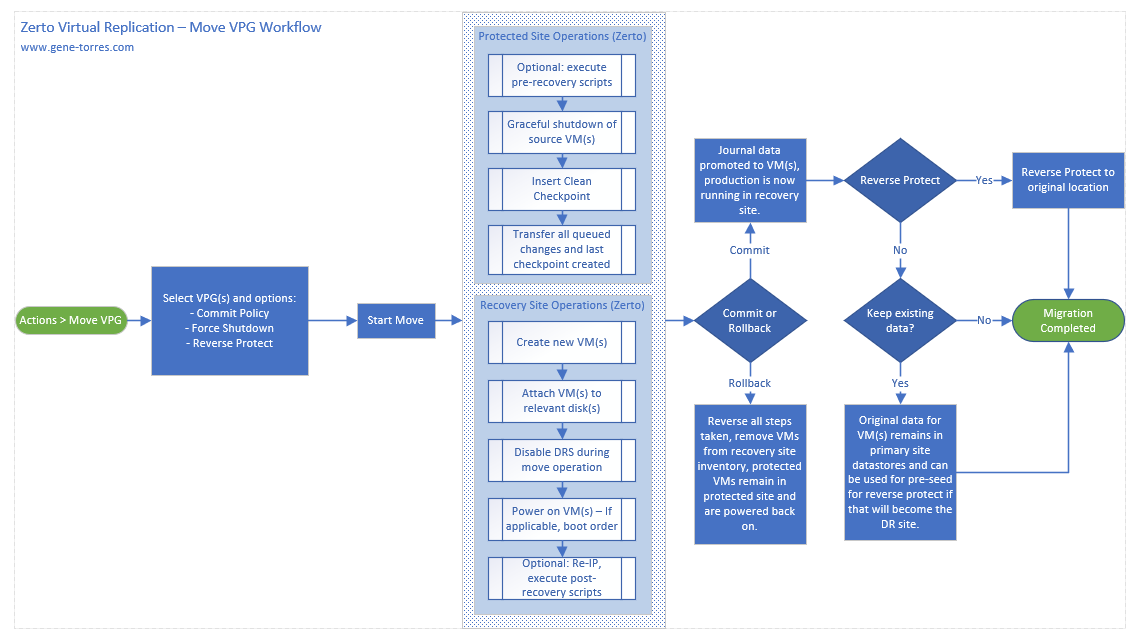
Once you’ve validated that your systems will successfully come up you can then schedule your migration. When you perform the migration into Azure, I recommend using the Move Operation (see image below), as that will be the cleanest way to get the system over to Azure in an application-consistent state with no data loss, as opposed to seconds of data loss and a crash-consistent state that the failover test, or failover live operations will give you.
Note: Before you run the Move Operation, it will be beneficial to uninstall VMware Tools on the VM(s) that you are moving to Azure. It has been found that not doing so will not allow you to uninstall them once in Azure.
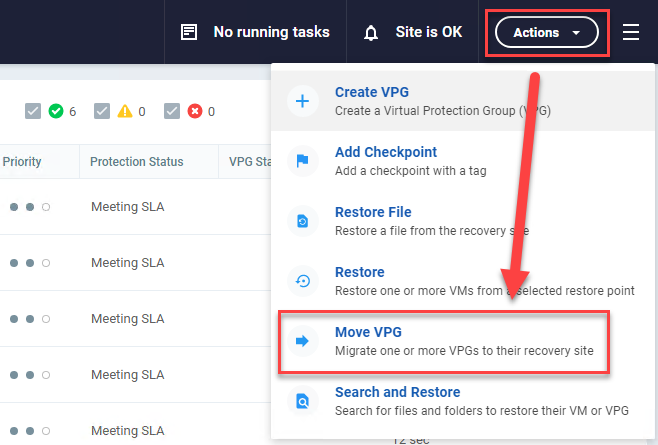
Recommendations before you migrate:
- Document everything you do to make this work. (it may come in handy when you’re looking for others to help you out)
- Be sure to test the migration beforehand using the Failover Test Operation.
- Check your Commit settings in Zerto before you perform the Move Operation to ensure that you allow yourself enough time to test before committing the workload to Azure. Current versions of Zerto default the commit policy to 60 minutes, so should you need more time, increase the commit policy time to meet your needs.
- Be sure to right-size your VMs before moving them to the cloud. If they are oversized, you could be paying way more in consumption than you need to with bigger instance sizes that you may not necessarily need.
That’s it! Pretty simple and straightforward. To be honest, obtaining a working copy of Windows Server 2003 R2 and the Hyper-V Integration Services took longer than getting through the actual process, which actually worked the first time I tried it.
If this works for you let me know by leaving a comment, and if you find this to be valuable information that others can benefit from, please socialize it!
Cheers!