Following an upgrade to ESXi 6.0 U2, this particular issue has popped up a few times, and while we still have a case open with VMware support in an attempt to understand root cause, we have found a successful workaround that doesn’t require any downtime for the running workloads or the host in question. This issue doesn’t discriminate between iSCSI or Fibre Channel storage, as we’ve seen it in both instances (SolidFire – iSCSI, IBM SVC – FC). One common theme with where we are seeing this problem is that it is happening in clusters with 10 or more hosts, and many datastores. It may also be helpful to know that we have two datastores that are shared between multiple clusters. These datastores are for syslogs and ISOs/Templates.
Note: In order to perform the steps in this how-to, you will need to already have SSH running and available on the host, or access to the DCUI.
Observations
- Following a host or cluster storage rescan, an ESXi host(s) stops responding in vCenter and still has running VMs on it (host isolation)
- Attempts to reconnect the host via vCenter doesn’t work
- Direct client connection (thick client) to host doesn’t work
- Attempts to run services.sh from the CLI causes script to hang after “running sfcbd-watchdog stop“. The last thing on the screen is “Exclusive access granted.”
- The /var/log/vmkernel.log displays the following at this point: “Alert: hostd detected to be non-responsive“
Troubleshooting
The following troubleshooting steps were obtained from VMware KB Article 1003409
- Verify the host is powered on.
- Attempt to reconnect the host in vCenter
- Verify that the ESXi host is able to respond back to vCenter at the correct IP address and vice versa.
- Verify that network connectivity exists from vCenter to the ESXi host’s management IP or FQDN
- Verify that port 903 TCP/UDP is open between the vCenter and the ESXi host
- Try to restart the ESXi management agents via DCUI or SSH to see if it resolves the issue
- Verify if the hostd process has stopped responding on the affected host.
- verify if the vpxa agent has stopped responding on the affected host.
- Verify if the host has experienced a PSOD (Purple Screen of Death).
- Verify if there is an underlying storage connectivity (or other storage-related) issue.
Following these troubleshooting steps left me at step 7, where I was able to determine if hostd was responding on the host. The vmkernel.log further supports this observation.
Resolution/Workaround Steps
These are the steps I’ve taken to remedy the problem without having to take the VMs down or reboot the host:
- Since the hostd service is not responding, the first thing to do is run /etc/init.d/hostd restart from a second SSH session window (leaving the first one with the hung services.sh restart script process).
- While running the hostd restart command, the hung session will update, and produce the following:
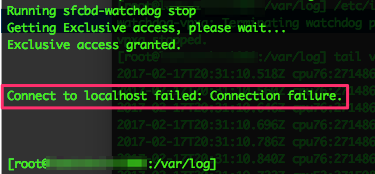
- When you see that message, press enter to be returned to the shell prompt.
- Now run /etc/init.d/vpxa restart, which is the vCenter Agent on the host.
- After that completes, re-run services.sh restart and this time it should run all the way through successfully.
- Once services are all restarted, return to the vSphere Web Client and refresh the screen. You should now see the host is back to being managed, and is no longer disconnected.
- At this point, you can either leave the host running as-is, or put it into maintenance mode (vMotion all VMs off). Export the log bundle if you’d like VMware support to help analyze root cause.
I hope you find this useful, and if you do, please comment and share!