The answer is yes, if you really wanted to… however, there’s another feature of Zerto that will allow you to perform a much “cleaner” migration of your VM(s) with a more planned approach.
This feature may not be easily located, as it’s found within the Actions menu in the Zerto UI, but it’s actually a very valuable one that basically allows you to migrate VMs from one location to another (cluster to cluster, vCenter to vCenter, vSphere <> Hyper-V, On-Prem to Public Cloud, Site to Site – even from one vendor’s hardware to another) with no data loss. That’s right, an RPO of ZERO.
Failover Live (FOL)
First off, since the title of this blog post mentions “Failover Live”, or as we abbreviate it as FOL, lets talk about that method first. What is the FOL process, and how does it work?
The FOL process is an operation that should be used following a disaster to recover your protected VMs in a recovery site, or in the event the protected site ZVM is not available. The main thing to note here is that when you execute a FOL, Zerto will default to the latest checkpoint, or you can select a previous checkpoint in time to recover to (usually within seconds of each other). Additionally, you have the option to either leave the VMs in the group running, power them off, or force a shutdown.
Essentially what this means is that when using FOL, Zerto is expecting that there’s been an unplanned environment disruption of some sort and you need to resume production as quickly as possible in your recovery site.
Here’s the workflow for a failover operation. You can download a PDF version of this diagram here.
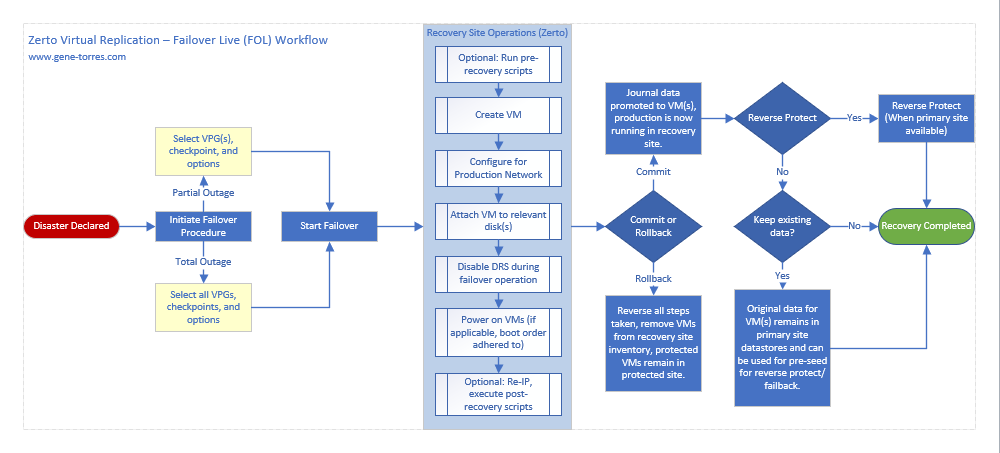
Please note, that the workflow objects in yellow include some decisions you will need to make based on your type of disruption as it relates to the power state of the VMs in your protected site (Shutdown (gracefully), Leave Powered On, or Force Shutdown).
Regarding my earlier comment about ZERO data loss, this method will only get you to the latest checkpoint when the outage was detected, or a previous checkpoint. You can choose what point in time to recover to, which in either option, will be a crash-consistent state which may not be desired for something like a migration project.
For additional detail about the Failover Live (FOL) process and how it works, including considerations, see the Zerto Virtual Manager Administration Guide for vSphere.
Move VPG
As opposed to an unplanned disruption to your environment, the “Move VPG” operation in Zerto is recommended when you’re performing a planned migration whether it be your DR site, public cloud, new hardware, or other datacenter. The difference here is that when you perform a planned migration of your virtual machine(s) to a recovery site, Zerto assumes that both sites are up and healthy and that you are performing a relocation of the virtual machine(s) in a controlled/orderly fashion – with the expectation of no data loss.
Here is the workflow for a Move VPG operation. You can download a PDF version of this diagram here.
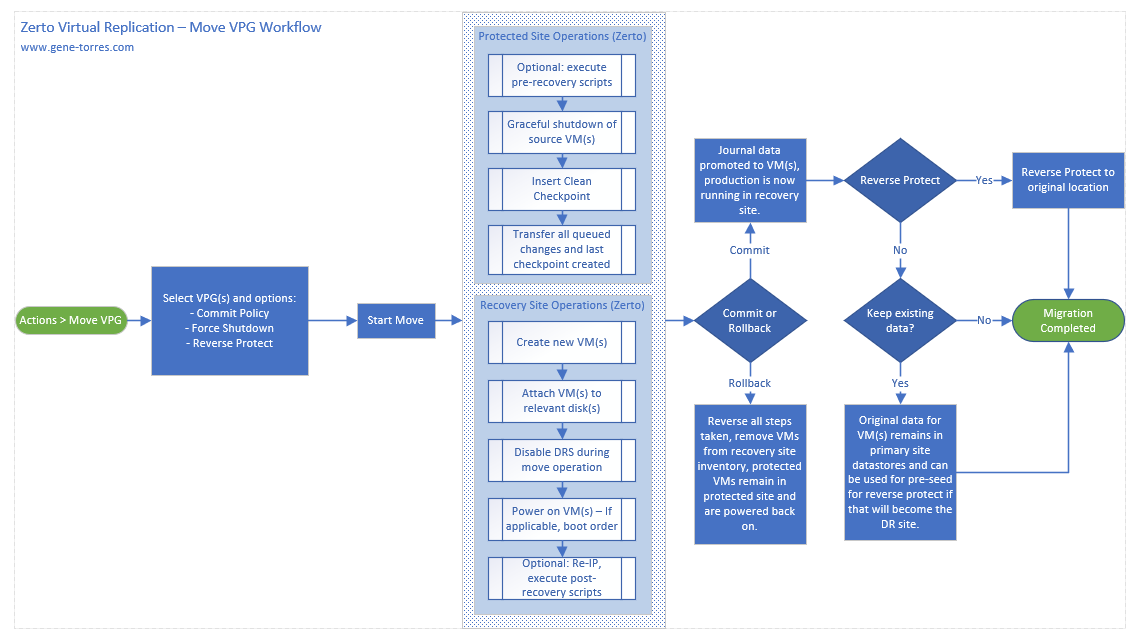
So as you can see from the workflow above, the steps are a bit different than a failover live, as there are actually some steps taken in the protected site before VMs are brought up in the recovery site to ensure that what is booted is in the exact same state as the source copy.
For additional detail about the Move VPG process and how it works, see the Zerto Virtual Manager Administration Guide for vSphere.
Summary
While you can still use the FOL process to migrate VMs from one location to another, there is still going to be some level of data loss and a crash consistent boot.
To ensure you don’t lose any data (even data that may be in memory at the time you perform a FOL), the “Move VPG” operation will take care of automating the safe/graceful shutdown of a VM and replicate any remaining data before powering up in the recovery site.
When performing either operation, be sure to verify your commit policy as well, because you would want to make sure that the recovered/migrated VM is in a usable state before committing it to the recovery location because once you commit the change, you must wait for promotion and reverse protection (delta sync) to take place before you can perform a failback. Both options will allow you the ability to rollback without commit, but behave differently in terms of the expected state of the protected site.