Zerto 9.0 went GA on July 13, 2021, and the official launch webinar was today (July 29, 2021), but if you missed it, you can head to the following URL and register to watch it on-demand:
https://www.zerto.com/page/zerto-9-live-demo-instant-ransomware-recovery/
While there are many new enhancements that I’m not going to cover here, this blog is specifically related to the changes made to the product to bring even more value, cost savings, and security to Amazon S3 repositories used with Zerto’s Long-term Retention (Backup).
Along with these changes, you can sure expect an updated technical document that will cover all the steps and requirements (in detail) to take advantage of the new features. I will also update this post with a link to the updated document once it becomes available.
Update: The latest version of the published document I wrote to accommodate this blog post titled “Deploy & Configure Zerto Long-term Retention for Amazon S3” can be found here: https://bit.ly/ZLTRAWSS3
Auto-Tiering for Data Backed up to Amazon S3
The first enhancement I want to cover here is automatic tiering of retention sets after they’ve aged, meaning Zerto will automatically move backup data from Amazon S3 Standard to Amazon S3 Standard-Infrequent Access, and then again (if desired) to Amazon S3 Glacier.
Here is what it looks like when creating a repository in Zerto:
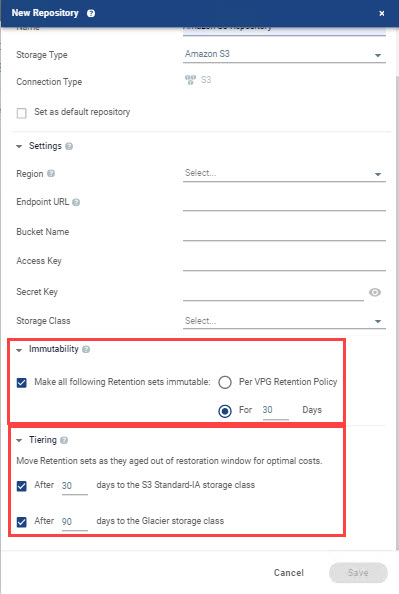
Now, when Zerto customers are backing up to Amazon S3, they can take advantage of better pricing as data ages, reducing cost and enabling more efficient use of storage. The new feature is enabled by default in a fresh install. If you are upgrading from a previous version, tiering will not be enabled by default, so you’ll need to enable it on an existing Amazon S3 repository, or create a new one. There are no additional configuration changes required to take advantage of this new feature.
Retention Set Immutability via Amazon S3 Object Lock
With Ransomware attacks continuing to rise (150% increase in 2020), the need to protect backup data via immutability becomes more important than ever. Customers can now specify whether or not they would like to enable immutability, which offers better protection from data either being deleted or otherwise compromised after it has been written.
While tiering doesn’t require any additional configuration, here are some things you’re going to need to know if you plan on using Zerto’s immutability feature with or without tiering:
- You cannot enable S3 Object Lock on an existing S3 bucket. This is an AWS limitation. You will need to create a new S3 bucket to store immutable backups, and then create a new repository in Zerto.
- You can have a repository that takes advantage of both of these new features, however, because of the object lock limitation on buckets (cannot be changed after the fact), you are still going to need a new repository (S3 bucket).
- There are some additional permissions for the IAM policy (covered below) required in order to take advantage of immutability.
- There are some additional features (covered below) you will need to enable on the S3 bucket to take advantage of immutability.
- If you’ve enabled S3 bucket encryption per my previous blog post in an earlier version of Zerto, the good news is that you can still have encryption enabled along with these new features.
Updated IAM Policy Permissions Required for Amazon S3
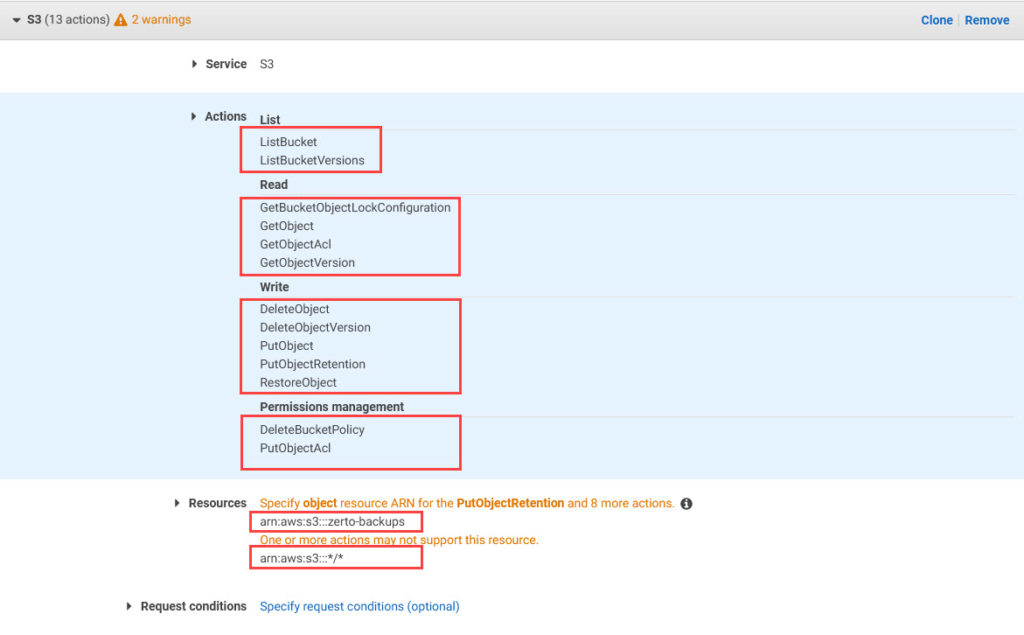
Here is the updated list of S3 permissions required in your IAM policy to take advantage of these new features. If you have an existing policy in use today, I’ve highlighted the additional permissions required (in bold), so you can easily update that policy. If you’d like a JSON version of the permissions for use with Amazon IAM policy creation, you can get the file from Zerto’s GitHub repo:
https://github.com/ZertoPublic/Zerto9-LTR-AWS-IAM-JSON
- S3:ListBucket
- S3:ListBucketVersions
- S3:GetBucketObjectLockConfiguration
- S3:GetObject
- S3:GetObjectAcl
- S3:GetObjectVersion
- S3:DeleteObject
- S3:DeleteObjectVersion
- S3:PutObject
- S3:PutObjectRetention
- S3:RestoreObject
- S3:DeleteBucketPolicy
- S3:PutObjectACL
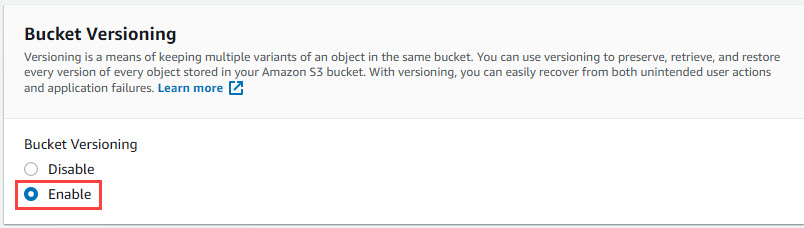
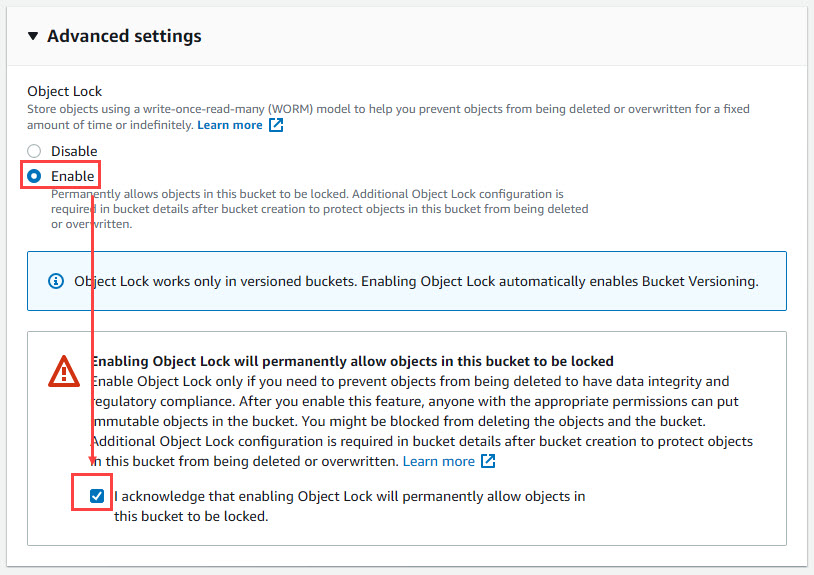
Amazon S3 Bucket Configuration for Immutability
In order to enable Immutability for the Amazon S3 bucket, you’re going to have to create a new bucket. Enabling S3 Object Lock has to be done at time of creation, so as you’re creating your new S3 bucket, be sure to include the following options:
- Enable S3 Bucket Versioning (This is required in order to enable Object Lock – See the screenshots below)
- Under Advanced Settings for the bucket, enable Object Lock, and tick the box to acknowledge that enabling Object Lock will permanently allow objects in this bucket to be locked.
There you have it! I’ve done quite a bit of testing with the new feature and am excited that we’re able to provide these new capabilities to meet our customer requirements and better safeguard them! We’ve also got similar enhancements for Azure users (however no immutability – yet), and I am planning on creating a technical document for setting this up in Azure, so stay tuned for that as well 🙂
If you have found this to be useful, please comment, or share so others are also aware. Thanks for reading 🙂